
들어가며
현재 요즘카페 팀의 DB는 서버와 같은 EC2에 존재하기 때문에 SPOF가 있어서 이를 제거하고자 하였다. 그러기 위해 DB를 다른 서버에 두기로 하였다.
이 과정에서 요즘카페 는 조회가 빈번하게 발생하고, 조회 도중에도 시청하지 않은 카페를 삽입해주는 로직이 실행되기 때문에 조회와 삽입을 DB Replication을 통해 성능을 향상시키고자 하였다.
Replication
한 서버에서 다른 서버로 데이터가 동기화 되는 것을 의미한다.
원본 데이터를 가진 소스서버에서 변경이 발생하면 복제 데이터를 갖는 레플리카 서버에는 이러한 변경 내역을 토대로 레플리카 서버의 데이터로 반영한다.
이 Replication을 하는 다양한 이유가 존재하는데
- 스케일 아웃: 서버 분리로 트래픽 분산
- 데이터 백업: 레플리카 서버를 이용해 시스템을 빠르게 복원할 수 있다.
- 데이터 분석: 분석용 쿼리만 별도로 실행되는 서버(DB) 구축이 가능하다.
- 지리적 분산: 물리적 거리만큼의 통신속도를 개선할 수 있다.
- 성능 향상: 쓰기 읽기 작업이 분산되는 만큼 서버의 부하를 줄일 수 있고 성능을 향상 시킬 수 있다.
카페를 읽는 과정에서 데이터 삽입이 발생한다. 사용자가 많아질 경우에 타 사용자로부터 발생하는 쓰기 작업이 읽기 작업에 영향을 미칠 수 있다고 판단되었고 이 부분에서 서버의 부하를 줄일 필요가 있다고 생각하였다. 서비스 자체가 조회가 우선시 되어야 하다보니까 이 부분이 느려질경우 사용자들이 이탈할 가능성이 높다고 판단하여 Replication을 통한 성능향상을 진행하였다.
스프링에서 작업
스프링에서 작업을 위해서는 master DB와 slave DB 간에 분기 처리를 진행해 주어야 한다. 또한 설정파일도 변경을 해주어야 하는데
spring:
datasource:
master:
jdbc-url: ~
username: ~
password: ~
driver-class-name: ~
slave:
jdbc-url: ~
username: ~
password: ~
driver-class-name: ~다음과 같은 방식으로 master, slave db의 경로를 설정해주었다. 이후 스프링에서 특정 조건에 따라 datasource를 변경할 것이다.
빈 등록
@Bean
@Qualifier(MASTER_DATA_SOURCE)
@ConfigurationProperties(prefix = MASTER_DATA_SOURCE_LOCATION)
public DataSource masterDataSource() {
return DataSourceBuilder.create()
.build();
}
@Bean
@Qualifier(SLAVE_DATA_SOURCE)
@ConfigurationProperties(prefix = SLAVE_DATA_SOURCE_LOCATION)
public DataSource slaveDataSource() {
return DataSourceBuilder.create()
.build();
}다음과 같은 방식으로 application.yaml 파일의 datasource들에 대해 빈 등록을 진행하였다.
동적 DataSource 변경
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
final boolean isReadOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
if(isReadOnly){
return SLAVE_DATA_SOURCE;
}
return MASTER_DATA_SOURCE;
}
}AbstractRoutingDataSource은 DataSource를 구현 클래스이며 동적으로 타겟 DataSource를 변경할 수 있는 클래스이다. 현재 context에 따라 동적으로 타겟 DataSource를 변경할 수 있다. 읽기 작업만 존재할 경우에는 Slave를 그 외에는 Master를 참조하도록 설정하였다.
DataSource 등록
@Bean
@Qualifier(ROUTING_DATA_SOURCE)
public DataSource routingDataSource(@Qualifier(MASTER_DATA_SOURCE) DataSource sourceDataSource,
@Qualifier(SLAVE_DATA_SOURCE) DataSource replicaDataSource) {
final RoutingDataSource routingDataSource = new RoutingDataSource();
final Map<Object, Object> dataSources = Map.of(MASTER_DATA_SOURCE, sourceDataSource,
SLAVE_DATA_SOURCE, replicaDataSource);
routingDataSource.setDefaultTargetDataSource(dataSources.get(MASTER_DATA_SOURCE));
routingDataSource.setTargetDataSources(dataSources);
return routingDataSource;
}위와 같은 코드를 통해 RoutingDataSource를 만들고 DataSources를 추가하였다. 이후 기본 DataSource는 Master로 설정을 해주었다.
LazyConnectionDataSourceProxy
@Bean
@Primary
public DataSource dataSource(@Qualifier(ROUTING_DATA_SOURCE) DataSource routingDataSource) {
return new LazyConnectionDataSourceProxy(routingDataSource);
}Spring이 트랜잭션에 진입하는 순간 이미 설정된 DataSource의 커넥션을 가져오고 트랜잭션을 식별하면 DataSource의 커넥션을 가져온다. 이럴 경우 지금처럼 master/slave DataSource 환경에서는 DataSource를 선택하는 분기가 불가능하기 때문에 미리 DataSource를 정하지 않도록 LazyConnectionDataSourceProxy를 사용하여 실제 쿼리가 실행될 때 Connection을 가져오도록 설정하였다.
이를 구현하면서 DataSource가 라우팅이 안되는 이유가 발생했는데 하단의 포스팅에 정리를 하였다!
DB에서의 작업
Master 서버 생성
my.cnf
server-id = {id로 사용하고 싶은 정수 값 중복되면 안됨}
log_bin = /var/log/mysql/mysql-bin.logserver_id는 복제에 참여한 MySQL 서버들이 고유하게 가지고 있는 식별 값이다.
Master 서버와 Slave 서버를 구별할 수 있도록 Slave 서버의 server_id를 바꾸어 주어야한다.
log_bin은 바이너리 로그파일의 형식이다.
mysql> CREATE USER '{사용자 이름}'@'{ 허용 IP 주소 (%) }' IDENTIFIED BY '{사용자 비밀번호}';
mysql> GRANT REPLICATION SLAVE ON {스키마 이름}.{테이블 이름} TO '{사용자 이름}'@'{ 허용 IP 주소 (%) }';
mysql> FLUSH PRIVILEGES;이후 다음과 같은 방식으로 Master에서 Replication 계정을 생성한다.
유저를 만들고 그 유저에게 Slave Replication 권한을 준다는 것이다.
mysql> SHOW master STATUS\G;
File은 바이너리 로그파일, Position은 바이너리 로그 파일 내부의 위치를 의미한다.
Slave 서버 생성
my.cnf
server-id = {id로 사용하고 싶은 정수 값 중복되면 안됨}
log_bin = /var/log/mysql/mysql-bin.logserver-id 값은 Master, Slave들과 겹치지 않는 고유한 값으로 지정해준다.
mysql> CHANGE MASTER TO MASTER_HOST='{MasterDB IP}', MASTER_PORT={MasterDB 포트번호}, MASTER_USER='{Master Replication 전용 유저 이름}', MASTER_PASSWORD='{Master Replication 전용 유저 비밀번호}', MASTER_LOG_FILE='{바이너리 로그 파일명}', MASTER_LOG_POS={POS 값};MASTER_USER와MASTER_PASSWORD는 앞서 Master 서버에서 생성해둔 Replication 전용 계정, 비밀번호를 입력한다.MASTER_LOG_FILE는 설정한 바이너리 로그 파일의 이름을 명시한다.MASTER_LOG_POS는 설정한 바이너리 로그 파일 내부 위치를 명시한다.
mysql> START slave;
mysql> SHOW slave STATUS\G;
Master 서버 쪽에 데이터를 추가하면 Slave 서버 쪽에도 곧장 반영되는 것을 확인할 수 있다.
복제 타입
소스 서버의 바이너리 로그에 기록된 변경 내역을 식별하는 방식에 따라 바이너리 로그 파일 위치 기반 복제, 글로벌 트랜잭션 ID 기반 복제 방식이 존재한다.
바이너리 로그 파일 위치 기반 복제
이 방식은 바이너리 로그 파일명 + 파일 내에서의 위치을 통해 이벤트를 식별한다. 이 위치 값은 실제 파일의 바이트 수를 의미한다.
레플리카 서버는 자신이 어떤 바이너리 로그 파일의 어떤 위치까지 복제했는지 정보를 관리한다.
바이너리 로그 파일 위치 기반 복제 에서는 server_id 값이 중요하다. 이벤트 별로 이벤트가 발생한 서버를 식별하기 위한 값인데, 이 값은 기본적으로 1이며 레플리케이션에 참여하는 모든 서버는 중복되지 않은 값을 가져야한다.
중복된 값을 가질 경우에는 레플리카의 I/O 쓰레드가 소스의 바이너리 로그 덤프 쓰레드로 부터 바이너리 로그를 읽어올 때 자기 자신으로부터 발생한 이벤트라고 간주하고 해당 이벤트를 가져오지 않는다.
글로벌 트랜잭션 ID 기반 복제
레플리케이션에 참여한 모든 서버들이 이벤트에 동일 식별자를 가지도록 하는 것이 글로벌 트랜잭션 ID 기반 복제이다. 이때 이벤트에 부여된 식별자를 GTID(Global Transaction IDentifier) 라고 한다.
복제의 Master 서버 뿐만 아니라 복제 대상에 속한 Replica 서버에서 고유한 식별자로 작용하여 기존의 binlog에서 읽은 시점을 가져오는 부분이 개선되었다.
나는 이중에서 바이너리 로그 파일 위치 기반 복제를 진행하였다.
- 아직 failover 상황에서 실제로 서비스를 복구하는 경험이 없어서 gtid가 가져다 주는 이점을 체감하지 못함
- 현재의 DB 토폴로지가 간단한 점
- 복제지연이 없어서 바이너리 로그가 바로 반영되는 점

다음과 같은 이유로 현재 서비스에서는 바이너리 로그 파일 위치 기반 복제 를 진행하였다. failover 상황을 직면한다면 GTID로 변경하지 않을까 싶다.
복제 토폴로지
다양한 복제 토폴로지가 존재하는데 우리팀은 싱글 레플리카를 선택하였다.
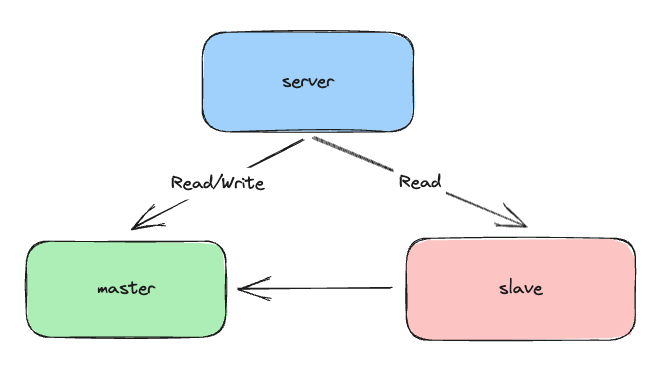
다음과 같은 구조를 선택하였다.
우리팀은 현재 서버 상 선택할 수 있는 구조가 몇가지 없었다.
이 중에서 Replication을 진행하면서 성능을 유지및 향상 시킬수 있는 싱글 레플리카를 선택하였다. 이 싱글 레플리카 토플로지에서는 레플리카 서버를 failover를 위해 대기하는 서버로 사용하지만 가용성 보다는 성능을 조금 더 향상시킬 수 있는 Replica를 Read전용 서버로써 만들었다.
결론
Replication의 결과로는 100명의 사용자가 카페 요청을 하고 중간 중간 시청하지 않은 카페가 삽입된다.
결과는 40% 정도의 성능이 향상한 것을 확인할 수 있었다.
TPS : 312 → 499
Response Time : 322 → 197
'코코코딩공부' 카테고리의 다른 글
| 테스트를 더 빠르게 진행시켜보자 (0) | 2023.10.21 |
|---|---|
| TestContainer 사용기 & 테스트 격리 (1) | 2023.10.16 |
| DataSource 라우팅이 안되는 이유. OSIV (1) | 2023.10.09 |
| Flyway 적용해보기 (0) | 2023.09.23 |
| N+1문제 개선기 (0) | 2023.09.11 |